The context
Turning a book into a watchable, narrated video series is one of the most manual jobs in content production. Each chapter has to be scripted, voiced, illustrated, captioned, mixed, and rendered, then repeated all over again for the next chapter. We set out to automate the whole pipeline end to end, keeping a human gate only where it matters most, the creative script, and letting the machine handle everything from PDF ingestion to a finished 1080p 16:9 master.
The problem, precisely
Long renders break inside a request. Generating voiceover, images, and AI motion, then stitching a full chapter, takes many minutes. Any approach that holds an HTTP connection open for the work falls apart on a redeploy, restart, or dropped connection.
Naive AI video bankrupts you. AI image-to-video is the single most expensive operation in the stack. Running it on every shot, with no cost ceiling and no visibility, leads to silent overspend that only shows up on the invoice.
Paying multiple times for the same render. Without idempotency, a redelivered or retried compile task re-runs the expensive FFmpeg assembly, paying three to four times over for one video that was already produced.
Automated scripts drift from the source. Letting a model both write and re-chop the narration means the spoken words can quietly diverge from the script a human approved, and diffusion models render any on-screen text as gibberish, which destroys credibility for an educational audience.
What we built ✓ verified in code
PDF-to-chapters ingestion pipeline
A Django REST and Celery backend ingests a book PDF, extracts text page by page with pypdf, and segments it into chapters using heuristic heading detection with an even-chunking fallback so the pipeline always yields at least one workable chapter. A cheap LLM call cleans each raw heading into a human-readable title.
Two-stage scripting with a human gate
An LLM writes a complete first-person voiceover script per chapter, opening on a hook and flowing through setup, tension, and payoff. The operator edits and approves it. Then plain code, not an LLM, chunks the approved script into verbatim, in-order scene beats, so the voiceover speaks exactly the approved words with no paraphrase. A separate LLM pass writes per-shot image and video prompts under one shared art direction.
Submit-and-poll media generation
Per-scene voiceover (ElevenLabs TTS), images (FLUX schnell), and optional AI motion (LTX) are all async-submitted to fal.ai and advanced by a Celery state machine that polls on a schedule. No HTTP call is ever held open for a render. Word-level TTS timestamps are captured as a free byproduct to drive caption sync, asset URLs are verified before a scene is trusted, and a failed shot is isolated on its own row while its siblings keep going.
Local FFmpeg assembly into two masters
Each chapter is stitched locally with FFmpeg: Ken Burns motion on stills, anti-slideshow grain and a breathing vignette, word-synced CapCut-style highlight captions, a ducked music bed normalized to YouTube's negative 14 LUFS standard, and intro/outro CTA cards. Every chapter ships as both a subtitled and a clean 1080p 24fps master. A 136-shot chapter compiled in roughly 24.6 minutes on a single box.
Cost and reliability engineering
Per-asset cost is tracked on every scene and surfaced at every screen. A hard cost ceiling refuses to run any image model priced above the approved limit, turning silent overspend into a loud, immediate failure. An idempotency guard plus a Redis single-flight lock stop the compile from ever paying multiple times for the same video, and heartbeats with lock-aware recovery let stalled chapters self-heal. We engineered per-chapter cost down roughly threefold, from about $8.70 to about $3.
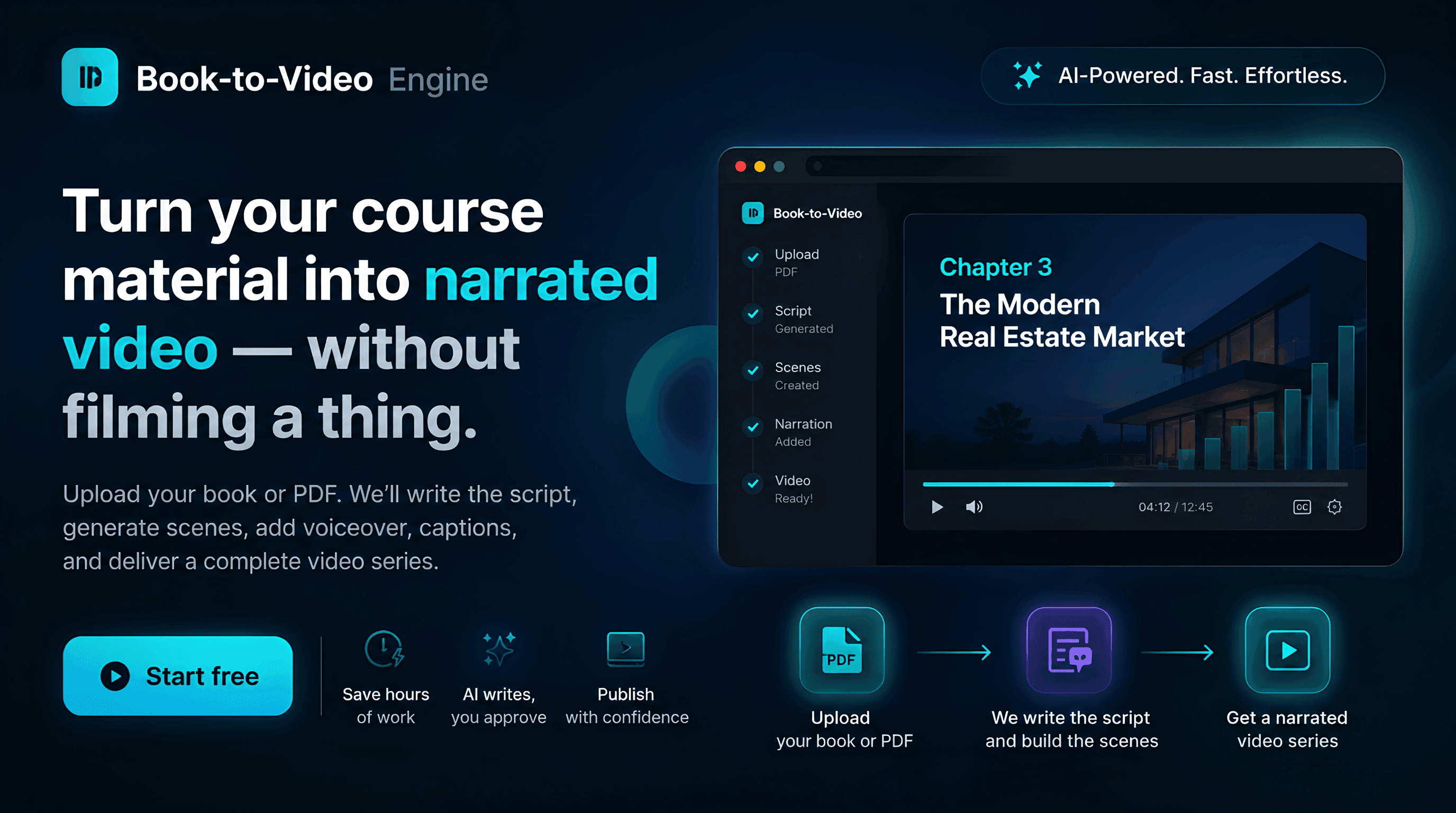
How it works
- 1
Ingest and draft. Upload a PDF on the dashboard. The backend extracts text, segments it into chapters, and drafts an editable first-person voiceover script for each chapter on the storyline screen.
- 2
Approve and break into scenes. The operator edits the script and art direction, then breaks it into scenes. Code deterministically chunks the approved text into verbatim narration beats, and an LLM adds one image and video prompt per beat under a shared art direction.
- 3
Generate media. Generating media elements fans out one task per scene to fal.ai for voiceover and images, plus opt-in AI motion. A polled Celery state machine advances each shot, verifies its asset URLs, and tracks per-asset cost live in the media workspace.
- 4
Compile and export. Compiling stitches the chapter locally in FFmpeg, applying Ken Burns motion, synced captions, a ducked music bed, loudness normalization, and CTA cards. The export screen shows live compile progress and offers subtitled and clean 1080p downloads with a Script and Media cost summary.
The outcome
The result is an autonomous YouTube-factory pipeline that takes a book PDF to a finished, narrated video series with a human approving only the script. By leaning entirely on aggregator APIs (OpenRouter for text, fal.ai for media) instead of running our own GPUs, making every long operation submit-and-poll, and treating cost as a first-class design constraint, we drove per-chapter production cost down from roughly $8.70 to about $3 (roughly $1 of Railway compute plus $2 of fal media). A 136-shot chapter renders in about 25 minutes on a single box. The pipeline is idempotent, so a redelivered compile never pays three or four times for the same video; self-healing, so stalled chapters auto-recover with friendly, actionable errors; and cost-guarded, so it refuses to silently run an expensive image model.
Screens